アンケート結果の背後にある要素を導き出す「R」を用いた因子分析手法
マーケティング、医療、教育など様々な分野で用いられるアンケート分析、しかし、アンケート分析は、単純にデータを集計して表層的に見える結果だけでは顧客(サンプル対象)の本質が読み取れないことが多くあります。
本記事では、因子分析とは何か、また、アンケート結果の背後にある要素(顧客の本質)を導き出す方法を、誰でも無料で使える統計解析ツール「R」を用いて解説いたします。Rのサンプルコード具体的に記述しています。ぜひ貴社業務に置き換えてお役立てください。
目次
因子分析とは
因子分析は、多くの変数から少数の因子(潜在変数)を抽出し、その因子を使って元のデータを説明するための解析手法です。たとえば、アンケートの質問内容(変数)から統計的に因子を抽出することで、アンケート結果の背後にある要素を推測することができます。
下記に、学生の学習動機を調査するために、6つのアンケート結果を因子分析した例をご紹介します。この分析では、6項目のアンケート結果から3つの因子を抽出することができました。このように、因子分析を行うことで、多くの変数を少数の因子にまとめることができます。
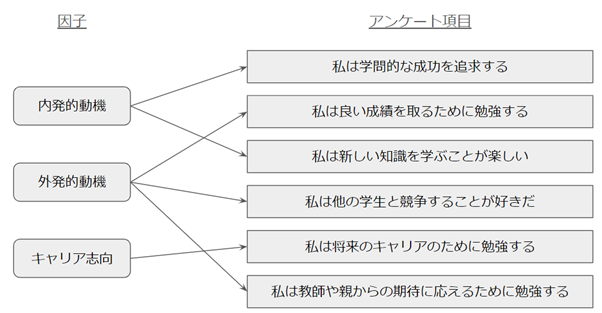
因子分析の適用例
因子分析は多岐にわたる分野で利用されています。以下にいくつかの例をご紹介します。
- 顧客の購買行動を理解するために、消費者アンケート項目から、「価格感度」「ブランド忠誠度」「品質重視」などの因子を特定し、マーケティング戦略を立てる
- 新製品開発のために、製品に関する多くの特性データを収集し、「機能性」「デザイン」「価格」などの主要な製品属性を特定し、新製品の設計に反映させる
- 健康促進プログラムを設計するために、健康行動や生活習慣に関するデータを収集し、「運動習慣」「食生活」「ストレス管理」などの主要な健康行動を特定する
上記例以外にも、変数の削減が必要な際に、分野を問わず広く活用されています。
統計解析ツール「R」とは?
Rは統計解析に特化したオープンソースのプログラミング言語です。データ分析やデータ可視化(グラフィック)のパッケージが豊富なのが特徴です。Rは、Excelで行えるデータ分析の基本的な処理はもちろん、クラスター分析や時系列分析などExcelでは難しい複雑なモデルも扱うことができます。
日本語に対応しているため、関数名や変数名でも日本語が使え、また、ソースコードがシンプルですので、非ITエンジニアでも扱いやすく、統計解析に広く利用されています。インストールすれば誰でも無料で使える点も大きなメリットです。

実践!Rを用いた因子分析の実行
ここからは、Rを使った因子分析の実例をご紹介します。今回は、以下のような5教科のテスト成績データに対して因子分析を行い、各科目の背後にある潜在能力を特定することを目的とします。
| 国語 | 算数 | 理科 | 社会 | 英語 |
|---|---|---|---|---|
| 78 | 42 | 41 | 64 | 74 |
| 76 | 45 | 69 | 60 | 76 |
| 70 | 44 | 51 | 70 | 81 |
| 84 | 64 | 48 | 74 | 80 |
| 61 | 63 | 44 | 63 | 83 |
| 78 | 65 | 53 | 66 | 75 |
| 72 | 45 | 46 | 60 | 57 |
| 63 | 42 | 69 | 74 | 85 |
| 79 | 60 | 56 | 55 | 62 |
| 80 | 60 | 52 | 66 | 78 |
因子分析は以下手順で行われ、本記事ではRを用いた分析方法をご紹介します。
- 因子数の決定
- 因子負荷の推定
- 因子軸の回転
- 因子の解釈
※なお本記事では、一つ一つの統計用語の説明は割愛します。
1.因子数の決定
因子数の決定方法には様々なアプローチがありますが、一般的には複数の結果を考慮して因子数を決定します。今回は以下の3つの手法を用います。
(1)ガットマン基準
(2)スクリーテスト
(3)平行分析
因子数には絶対的な正解は存在しません。そのため、通常はこれらの手法の結果を参考にしながら、最終的に納得のいく「因子の解釈」が得られるまで因子数を変更して検討を続けます。
(1)ガットマン基準
ガットマン基準は、観測変数の相関行列の固有値を基に因子数を決定する方法で、固有値が1以上の因子の数を因子数とします。Rでは以下のように実行します。
まずは、データを読み込みます。
df_score<- read.csv("5科目成績.csv")
次に、観測変数の相関行列を求めます。
cor.df_score <- cor(df_score)
最後に、固有値の計算を行い、結果を表示します。
print(eigen(cor.df_score))
すると、以下のような結果が得られます。
| 1.89 | 1.36 | 0.63 | 0.58 | 0.53 |
※実際のRの実行結果はテキストで表示されますが、本記事では見やすさを優先し、表形式で結果をご紹介します。
上記の結果から、値が1を超える固有値が2つあるため、ガットマン基準では因子数は2となります。
(2)スクリーテスト
スクリーテストは、固有値をプロットし、傾きがなだらかになる点を因子数とする手法です。このプロットはスクリープロットと呼ばれます。
Rでは以下のようにスクリープロットを作成します。
library(psych)
VSS.scree(df_score)
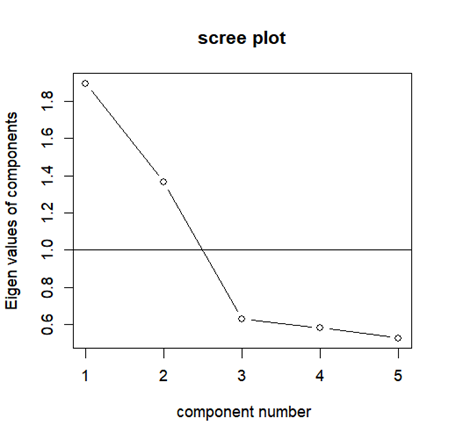
このグラフでは、第三因子以降で傾きがなだらかになっているため、スクリーテストでは因子数が2となります。
(3)平行分析
平行分析は、ランダムデータの固有値と実際のデータの固有値を比較し、実際のデータの固有値がランダムデータの固有値を超える因子の数を因子数とする手法です。
平行分析を実行し、図を表示するためのRスクリプトは以下の通りです。
fa.parallel(df_score, fm="ml", fa="pc", n.iter=100)
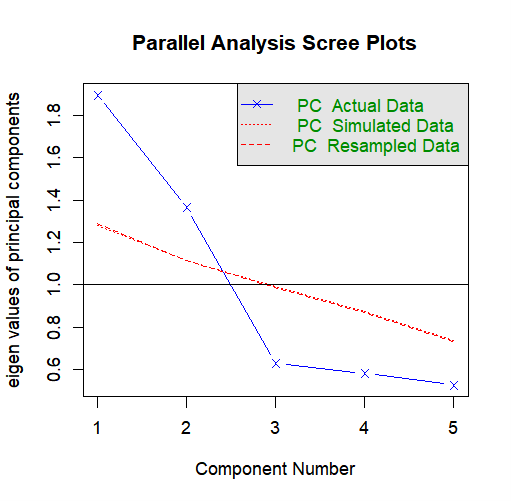
このグラフから、実データの固有値が乱数データの固有値よりも大きくなっている(青いプロットが赤い線よりも上に位置している)のは2つの因子のため、平行分析では因子数は2と判断できます。
今回、(1)ガットマン基準、(2)スクリーテスト、(3)平行分析の結果、すべてにおいて因子数が2と出たため、因子数を2として次の手順に進みます。
2.因子負荷の推定
因子負荷は、各因子が各変数に対してどの程度影響力を持っているかを示す指標です。今回、因子が2つ、変数が5つであるため、合計10個の因子負荷が存在します。因子負荷の値を見て、各因子がどのような概念を表しているかを判断します。
以下のスクリプトで、因子負荷の計算および結果の表示ができます。
fa.df_score <- fa(df_score, nfactors=2, fm="ml", rotate="none")
print(fa.df_score, sort=TRUE, digits=3)
| ML1 | ML2 | |
| 社会 | 0.69 | 0.03 |
| 英語 | 0.67 | -0.12 |
| 国語 | 0.57 | -0.24 |
| 理科 | 0.13 | 0.66 |
| 算数 | 0.25 | 0.51 |
この結果において、ML1の列は第1因子の因子負荷、ML2の列は第2因子の因子負荷を示しています。この結果を基に解釈を行うことも可能ですが、一般的には次に因子軸の回転を行ってから解釈を行います。因子軸の回転によって、因子の解釈がより明確になり、各因子の意味がより理解しやすくなります。
3.因子軸の回転
因子軸の回転を行うことで、結果の解釈が容易になります。これは計算結果そのものを根本から変えるわけではなく、人間が解釈をしやすくするために行うものです。
以下のスクリプトで、因子軸の回転を実行し、その結果を表示することができます。
library(GPArotation)
fa.dkk2 <- fa(df_score, nfactors=2, fm="ml", rotate="promax")
print(fa.dkk2, sort=TRUE, digits=3)
| ML1 | ML2 | |
| 社会 | 0.68 | 0.00 |
| 英語 | 0.65 | 0.16 |
| 国語 | 0.63 | -0.14 |
| 理科 | -0.09 | 0.68 |
| 算数 | 0.07 | 0.55 |
因子軸の回転を行うことで、若干ではありますが、先ほどよりも一方の因子からの影響が強く、もう一方からの影響が0に近づく結果が得られました。このように、1つの因子以外からは影響を受けない結果が得られることで、因子の解釈がより容易になります。これを基にして、因子の具体的な解釈を行います。
4.因子の解釈
先ほどの結果より、因子の解釈を行います。因子の解釈とは、それぞれの因子が何を表しているかを推測する作業です。因子分析の結果に基づく解釈は主観的であり、分析者によって異なる場合があります。一意の正解は存在せず、適切な解釈が難しい場合には、因子数の変更や因子軸の回転パラメータの調整を試みることで、異なる解釈が得られる可能性があります。
先ほどの結果を基に因子の解釈を行うことも可能ですが、可視化をすることで解釈がより容易となります。以下のスクリプトで、因子分析の結果を可視化できます。
まずは因子負荷量を抽出し、データフレームに変換します。
loadings <- fa.df_score$loadings
loadings_df <- data.frame(
Variable = rownames(loadings),
ML1 = loadings[, 1],
ML2 = loadings[, 2]
)
その後、可視化を行います。
library(ggplot2)
library(ggrepel)
ggplot(loadings, aes(x = ML1, y = ML2)) +
geom_point(aes(color = rownames(loadings)),size = 5) +
geom_text_repel(aes(label = rownames(loadings)), size = 5) +
theme_minimal() +
labs(title = "因子負荷量のプロット", x = "因子1", y = "因子2") +
theme(legend.position = "none")
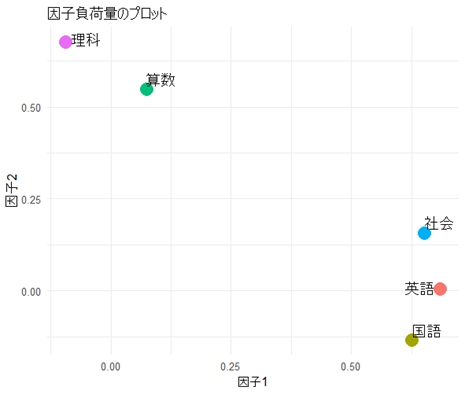
この結果より、以下がわかります。
- 因子1から強い影響を受けているのが、国語・英語・社会
- 因子2から強い影響を受けているのが、算数・理科
これに基づく解釈は次の通りです。
- 第一因子は、文系科目の能力を示し、国語・英語・社会が強い影響を受けている
- 第ニ因子は、理系科目の能力を示し、算数・理科が強い影響を受けている
このように因子分析を行うことで、単にデータを視覚的に把握するだけでなく、人間の感覚に頼らずに、変数を体系的に分類し、解釈を行うことができます。変数が多く結果の解釈が難しい場合や、背後にある潜在的な要素を明らかにしたい場合に、因子分析は非常に有効な手法です。
本記事では、初めての方にもわかりやすく、5教科のテスト成績を例に、Rを用いた因子分析手法の一部をご紹介しました。Rでは、もっと深く様々なことを分析することが可能です。貴社のアンケートデータや購買履歴データを分析してみてはいかがでしょうか?
アドバンリンクでは、データ分析支援サービスのほか、初心者からの「R基本操作セミナー」や、「多変量解析セミナー」を定期的に開催しています。R操作についてもっと深く学びたい方、CRM分析など実務に直結するデータ分析手法を学びたい方をサポートしております。企業向けにカスタマイズしたオンサイトセミナーも実施しております。どうぞお気軽にご相談ください。

分析設計からリソース提供までデータ分析に関わる全てをサポート
アドバンリンクのデータ分析サービスの特徴
- CRM業界トップクラスの分析チーム
- データサイエンティスト、CRMコンサルタント多数在籍
- 分析トレーニングサービス実施
データ分析セミナー
- 顧客データ活用ノウハウセミナー
- R基本操作セミナー
- Python基本操作セミナー
- Tableu基本操作セミナー
- 多変量解析セミナー
更新日:2025/1/27/公開日:2024/8/5