Pythonを用いたCS分析
CSとは、Customer Satisfaction(カスタマーサティスファクション)=顧客満足度のことを指します。商品・サービスを提供していく上で、しばしば重要な指標となります。本記事では、顧客満足度調査をアンケートにて行い、CSの総合評価を向上させるためには、どの項目から改善に注力していけばよいのかを明らかにする手法をご紹介します。Pythonで実際に手を動かせるよう、サンプルコードを記述していますので、ご参考ください。
目次
はじめに
本記事では、架空のレストランのCS分析(顧客満足度分析)を行います。「ご飯の味」「レストランの清潔さ」「店員の対応」など、12項目のアンケー ト調査データを基に、どの要素の改善が総合評価の向上に最も寄与するのかを、 4つのステップで判断していきます。
今回用いるデータ
以下のようなアンケートを行ったと仮定し、CS分析を用いて総合評価の向上に向けた改善項目の優先順位を決定します。なお、全てのアンケートは5点満点で評価がされているものとします。
アンケート内容
Q1: 味には満足しましたか
Q2: 店舗は清潔でしたか
Q3: スタッフの対応は良かったですか
Q4: 注文のスピードには満足しましたか
Q5: メニューの種類に満足しましたか
Q6: 価格に対する満足度はどうですか
Q7: 施設の快適さはどうですか
Q8: 店舗の雰囲気はどうですか
Q9: トイレの清潔さに満足しましたか
Q10: 店内の音量は適切でしたか
Q11: 特別なリクエストへの対応は良かったですか
Q12: 総合的な満足度はどうですか
総合評価: 総合評価を教えてください
アンケート結果
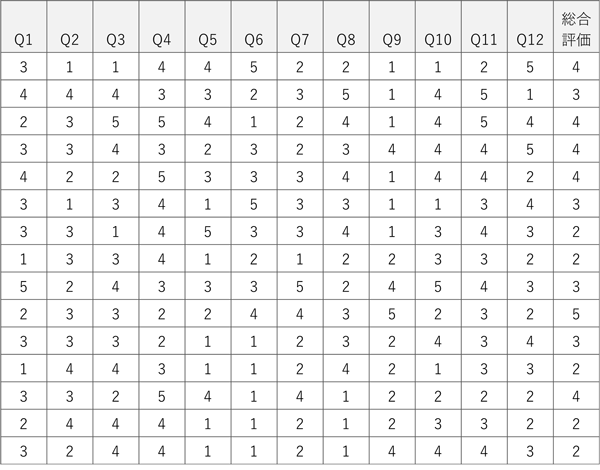
CS分析
データ分析の流れとしては、各アンケート項目の改善余地(平均値の低さ)と、各アンケート結果と総合評価との相関係数を基に、改善の優先順位を決定していきます。
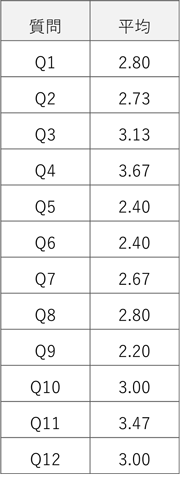
1.各アンケート項目の平均値の集計
まず、各アンケート項目(Q1〜Q12)の平均値を計算します。これにより、各項目の全体的な満足度を把握することができます。平均値が低い項目は、顧客満足度が相対的に低いことを示しており、改善の余地が大きいと考えられます。
# データ読み込み
cs = pd.read_csv("cs.csv")
# '総合評価'列を別に保存
total_score = cs['総合評価']
# '総合評価'列を削除
cs_without_total = cs.drop(columns=['総合評価'])
# 各質問の平均スコアを計算
average_score = cs_without_total.mean(numeric_only=True)
# データフレームに変換し、長い形式に変換
average_score_df = average_score.reset_index()
average_score_df.columns = ['質問', '平均']
# 結果表示
print(average_score_df)
# 棒グラフの作成
plt.bar(average_score_df.質問, average_score_df.平均)
plt.xlabel('質問')
plt.ylabel('平均値')
# グラフの表示
plt.show()
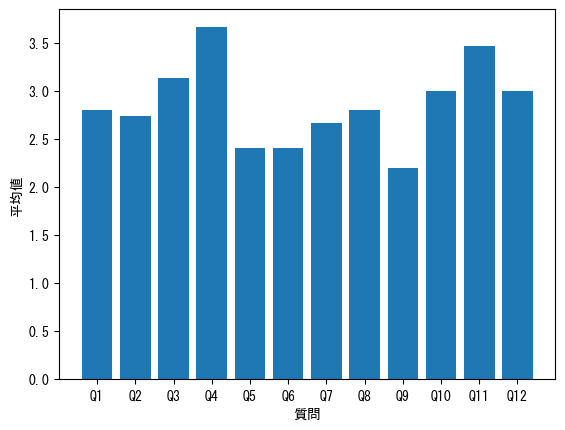
この結果から、Q4の平均値が最も高く、Q9の平均値が最も低いことがわかります。アンケート全体の平均値を向上させるためには、平均値が低い項目から対応していけば良いかもしれませんが、今回は総合評価を上げることが目的のため、次の相関分析も行います。
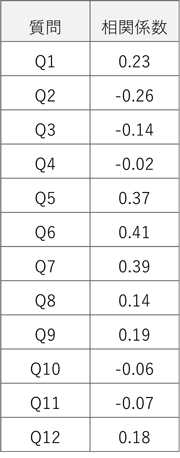
2.総合評価との相関関係の分析
各アンケート項目(Q1〜Q12)と総合評価との相関関係を分析します。相関係数を計算することで、どの項目が総合評価に強く影響しているかを把握します。相関係数は、-1から1の値を取り、1に近いほど強い正の相関を示し、-1に近いほど強い負の相関を示します。相関係数が高い項目は、総合評価に大きな影響を与えていると判断できます。
# 各質問との相関係数を計算
correlation_with_CS = cs_without_total.apply(lambda x: x.corr(total_score, method='pearson'))
# データフレームに変換し、長い形式に変換
correlation_df = correlation_with_CS.reset_index()
correlation_df.columns = ['質問', '相関係数']
print(correlation_df)
# 棒グラフの作成
plt.bar(correlation_df.質問, correlation_df.相関係数)
plt.xlabel('質問')
plt.ylabel('平均値')
# グラフの表示
plt.show()
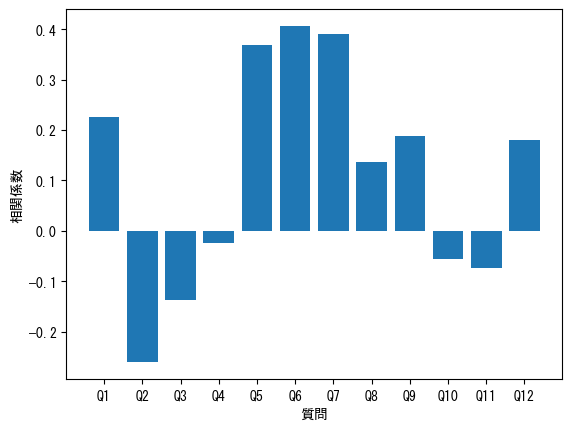
この結果により、総合評価との相関係数は、Q6が最も高く、Q2が最も低いことがわかります。この結果だけで改善項目を決定する場合は、相関係数が高い項目から順に改善を進めることで、総合評価の向上が期待できます。ただし、総合評価を最大化するためには、相関係数が高く、かつ改善の余地が大きい(平均値が低い)項目を特定する必要があります。
3.平均値と相関係数の関係を可視化
上記2つの結果をまとめ、散布図としてプロットします。
# 相関係数と平均スコアを内部結合
result_df = pd.merge(average_score_df, correlation_df, on='質問')
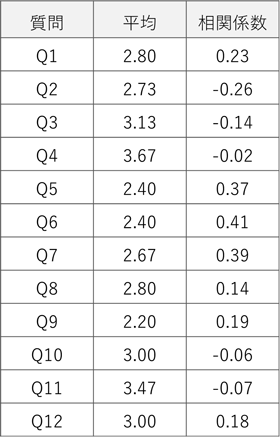
print(result_df)
# 可視化
plt.figure(figsize=(6, 6)) # 正方形の図のサイズを指定
# 色を指定
sns.scatterplot(data=result_df, x='相関係数', y='平均', s=100, color='blue')
# 各点にラベルを追加
for i in range(result_df.shape[0]):
plt.text(result_df['相関係数'].iloc[i], result_df['平均'].iloc[i], result_df['質問'].iloc[i],
verticalalignment='bottom', horizontalalignment='right', fontsize=10)
plt.xlabel('相関係数')
plt.ylabel('平均')
plt.grid(True)
plt.tight_layout()
plt.show()
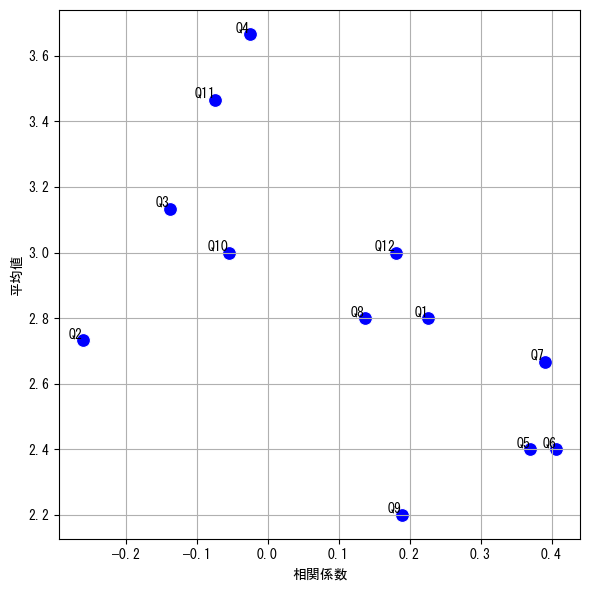
この散布図では、「総合得点との相関係数が高く」「平均値が低い」右下の項目に注力するのが効果的だと考えられます。ただし、右下には多くの項目が存在するため、明確な優先順位をつけるために、次頁に示す改善度という指標を導入して分析を行います。
4.改善度計算
まず、相関係数と平均値をそれぞれ偏差値に変換し、その後、再度散布図にプロットします。データを偏差値に変換するだけなので、散布図の見た目はほとんど変わりません。また、相関係数の偏差値を「重要度」、平均値の偏差値を「満足度」と名付けます。偏差値は、平均が50、分散が10になるように調整されます。
# 偏差値を計算する関数
def calculate_z_score(x):
mean_x = x.mean()
sd_x = x.std()
z_score = 50 + 10 * (x - mean_x) / sd_x
return z_score
# 偏差値を計算
result_df['満足度'] = calculate_z_score(result_df['平均'])
result_df['重要度'] = calculate_z_score(result_df['相関係数'])
# 不要な列を削除
result_df = result_df.drop(columns=['相関係数', '平均'])
# 可視化
plt.figure(figsize=(6, 6)) # 正方形の図のサイズを指定
sns.scatterplot(data=result_df, x='重要度', y='満足度', s=100, color='blue') # 色を指定
# 各点にラベルを追加
for i in range(result_df.shape[0]):
plt.text(result_df['重要度'].iloc[i], result_df['満足度'].iloc[i], result_df['質問'].iloc[i],
verticalalignment='bottom', horizontalalignment='right', fontsize=10)
plt.xlabel('重要度(偏差値)')
plt.ylabel('満足度(偏差値)')
plt.title('重要度と満足度の散布図(偏差値)')
plt.grid(True)
plt.tight_layout()
plt.show()
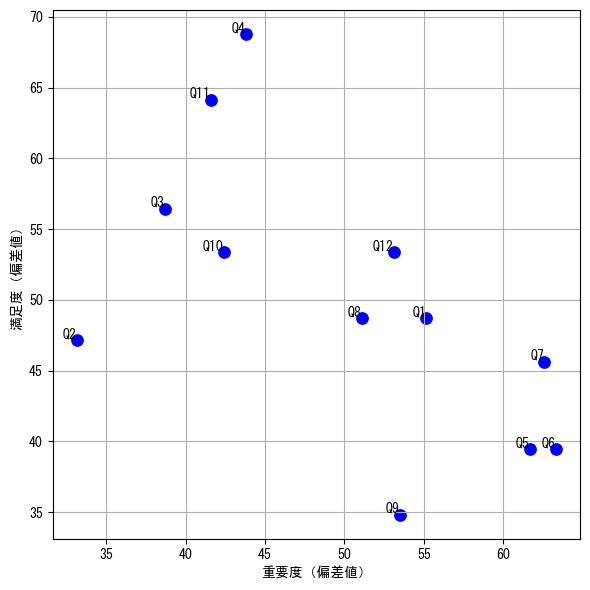
改善度の基本的な考え方は、上記の散布図において「どれだけ右下に位置するか」を数値で示す方法です。以下の図では、赤い点が各項目の位置を示しています。これらの点について、「中央(50,50)からの距離」と「中央から右下45度に引いた直線との角度」を計算し、この2つの値から改善度を算出します。
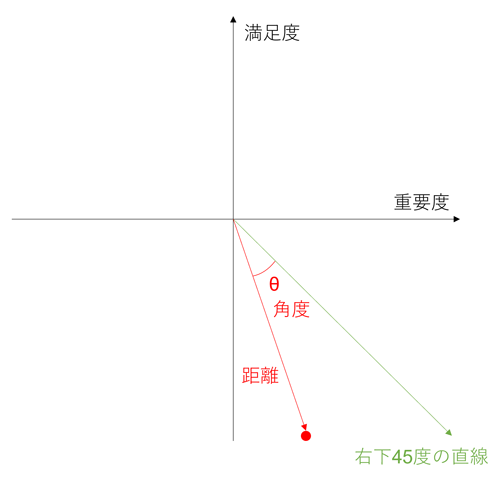
中央からの距離は、以下の方法で計算できます。
result_df['距離'] = np.sqrt((result_df['満足度'] - 50) ** 2 + (result_df['重要度'] - 50) ** 2)
角度については、自作の関数を用いて計算します。
def calculate_angle(x, y):
A_x, A_y = 30, -30
B_x, B_y = x - 50, y - 50
# アークタンジェントを使用して角度を計算
angle_rad = np.arctan2(B_y, B_x) - np.arctan2(A_y, A_x)
# ラジアンから度に変換
angle_deg = np.degrees(angle_rad)
# 角度を正の値に調整(0から360度の範囲にするため)
if angle_deg < 0:
angle_deg += 360
return angle_deg
# 角度算出
result_df['角度'] = np.vectorize(calculate_angle)(result_df['重要度'], result_df['満足度'])
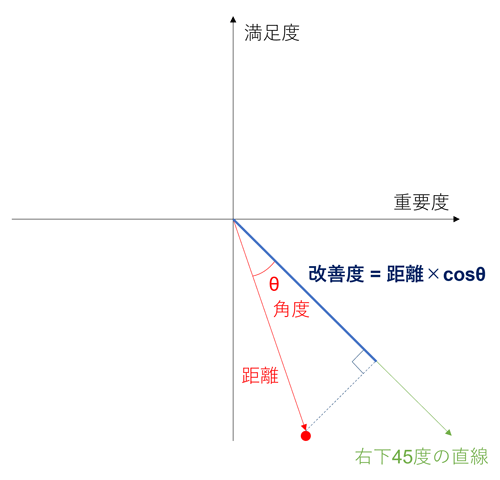
次に、この角度を基に修正指数を計算します。修正指数としては、角度のコサイン値(cos値)を 使用します。
result_df['修正指数'] = np.cos(result_df['角度'] * np.pi / 180)
最後に、距離に修正指数を掛けることで、改善度を求めます。
result_df['改善度'] = result_df['距離'] * result_df['修正指数']
改善度を図中に表すと、以下の青い直線の長さとなります。この直線は、中央の点から各項目に 引いた直線を、右下45度の直線に対して投影した長さを示しています。青い線が長いほど、改善 度が高いと言えます。
計算結果に基づいて、改善度の高い順に並べ替えを行います。
result_df.sort_values("改善度", ascending=False, inplace=True)
print(result_df)
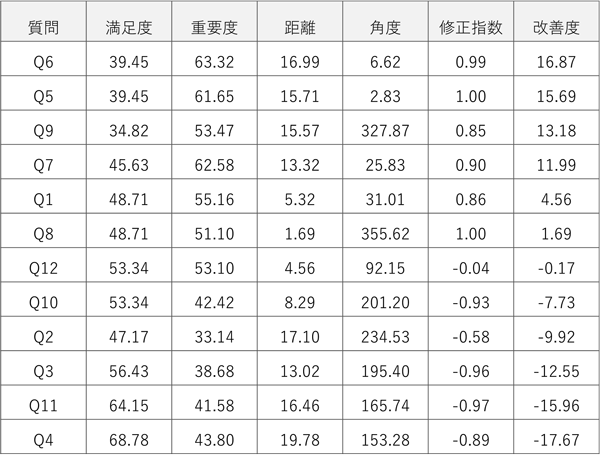
結果を見ると、改善度はQ6、Q5、Q9、Q7、Q1の順に高くなっており、上記散布図の右下の項目ほど改善度が高いことがわかります。したがって、このレストランでは、以下の順序で改善に取り組むことで、総合満足度を効果的に向上させることができると言えます。
Q6: 価格に対する満足度はどうですか
Q5: メニューの種類に満足しましたか
Q9: トイレの清潔さに満足しましたか
Q7: 施設の快適さはどうですか
Q1: 味には満足しましたか
終わりに
本記事では、アンケートデータを例に、Pythonを用いたCS分析手法の一部をご紹介しました。Pythonでは、もっと深く様々なことを分析することが可能です。 Pythonを用いて貴社のアンケートデータを分析してみてはいかがでしょうか?
アドバンリンクでは、データ分析支援サービスのほか、初心者からの「Python基本操作セミナー」や、「多変量解析セミナー」を定期的に開催しています。Python操作についてもっと深く学びたい方、あるいは、RやTableauなど他の分析ツールの操作を習得したい方、CRM分析など実務に直結するデータ分析手法、データの読み取り方を学びたい方をサポートしております。企業向けにカスタマイズしたオンサイトセミナーも実施しております。どうぞお気軽にご相談ください。

アドバンリンクのデータ分析サービスの特徴
- CRM業界トップクラスの分析チーム
- データサイエンティスト、CRMコンサルタント多数在籍
- 分析トレーニングサービス実施
データ分析セミナー
- 顧客データ活用ノウハウセミナー
- R基本操作セミナー
- Python基本操作セミナー
- Tableu基本操作セミナー
- 多変量解析セミナー
公開日:2024/9/24